



What used to feel optional is now expected. Speech recognition technology has moved from a convenience feature to a core part of how people interact with software, both at work and at home.
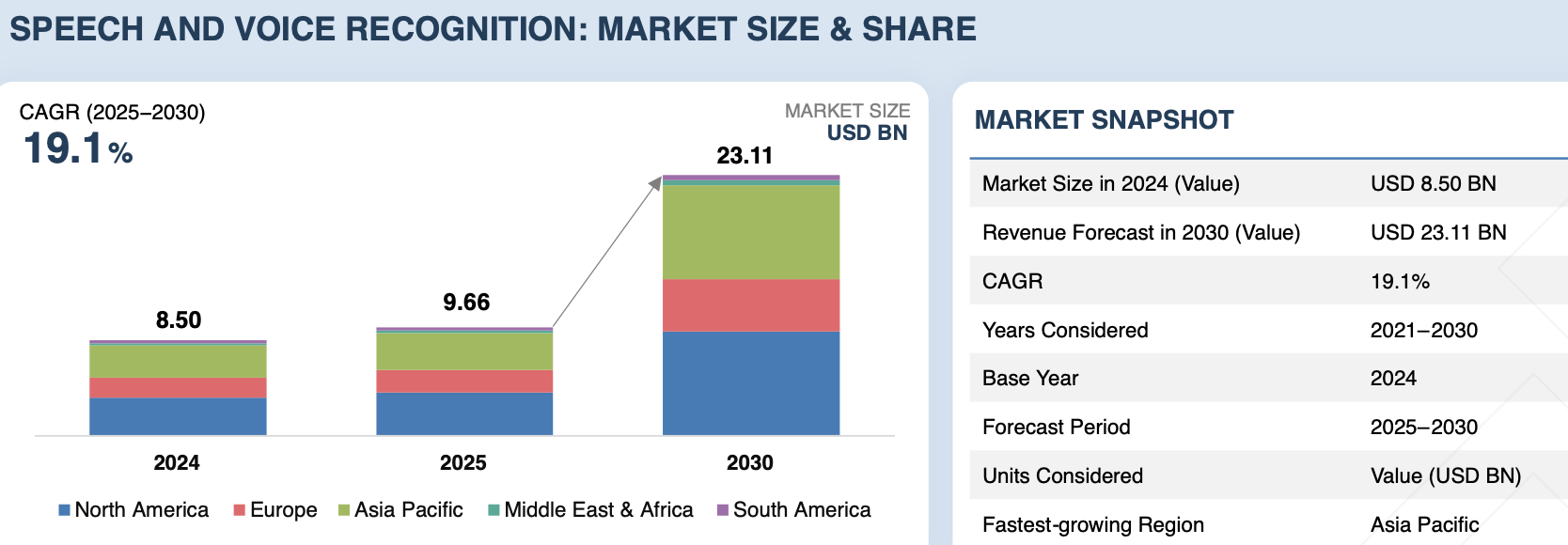
Market data reflects a broader trend. The global speech and voice recognition market was valued at almost $10 billion in 2025 and is projected to reach nearly $23 billion by 2030. Adoption is already widespread. As of the end of 2025, around 62% of adults in the United States regularly use voice assistants built into products from Apple, Amazon, and Google. What once felt new now feels normal. People expect technology to respond like this.

It’s not surprising that expectations carry over into business environments. Automatic speech recognition reduces headaches in routine work by turning spoken language into structured data. Meetings can be transcribed without manual effort. Customer calls can be indexed and analyzed instead of disappearing once they end. Employees can record actions or retrieve information without stopping their workflow to type or navigate menus. In each case, speech works as a faster way to give input, not as a substitute for human judgment.
In this article, we’ll examine how AI speech recognition systems are changing business workflows and personal routines. Let’s see in more detail.
What is speech recognition in AI?
Speech recognition in AI refers to a system’s ability to convert spoken language into text or structured commands that software can act on. In practical terms, it allows computers and devices to listen, interpret what was said, and respond in a useful way.
These systems rely on machine learning models and neural networks trained on large collections of recorded speech. The models learn patterns in pronunciation, timing, accents, and context. When someone speaks, the system breaks the audio into small units, matches them against learned patterns, and predicts the most likely words and meanings. Over time, exposure to more data improves accuracy and consistency.
Modern speech recognition systems do more than identify isolated words. It can handle full sentences, account for pauses or background noise, and adjust to different speakers. That progress is why speech recognition now supports everyday tools like virtual assistants, call transcription systems, and voice-controlled software used in work environments.
The speech and voice ecosystem is made up of several layers that depend on each other to work well.


Image source
Hardware manufacturers build the devices that capture sound, from microphones to in-car systems. Companies like Samsung, LG, and Bose focus on audio quality, noise reduction, and reliability at the source.
Software providers sit on top of that hardware. Platforms from Apple, Google, Microsoft, IBM, and Amazon Web Services handle speech recognition, language understanding, and integration with applications.
System integrators connect these capabilities to real business workflows. They tailor speech systems to specific environments, tools, and constraints so they work beyond demo and lab conditions.
End users are where everything comes together. Organizations such as AT&T, Comcast, Tesla, and BMW use speech technology to support customers, operate services, and build voice-driven experiences into everyday products.
The ecosystem only works when all of these layers are aligned. Weak audio, poor models, or shallow integration can break the experience just as easily as a missing feature.
How does speech recognition in AI work?
Speech recognition systems follow a multi-step process that turns raw audio into usable text or actions. Each step handles a specific part of the problem, and the system only works well when all of them function together.
The process starts with audio input. When you speak, a microphone captures your voice as a digital audio signal. This signal is the only raw material the system has to work with, which is why microphone quality and background noise matter more than most people expect.
Next comes feature extraction. The system analyzes the audio signal and breaks it into small segments that represent measurable characteristics of sound, such as frequency, pitch, and timing. These features strip away unnecessary detail and keep the information that helps distinguish one sound from another.
The third step is acoustic modeling. Here, neural networks analyze the extracted features and map them to phonemes, which are the smallest units of sound in spoken language. For example, the “s” sound in “son” and the “h” sound in “horse” are treated as distinct phonemes. This step focuses on how speech sounds, not what it means.
After that, the system applies language modeling. The language model takes the stream of phonemes and determines the most likely words and sentences based on context. This is how the system decides whether a sound sequence maps to “recognize speech” or something that only sounds similar. Context, grammar, and probability all play a role here.
The final step is text output or action execution. The system converts the recognized words into text or triggers a command inside an application. If you say, “Set a timer for 10 minutes,” the system does not just transcribe the sentence. It identifies intent and passes the instruction to the part of the system responsible for setting timers.
What makes modern speech recognition systems effective is not any single step, but how well these steps are connected. When audio capture, modeling, and context work together, spoken language becomes a reliable way to interact with software instead of a fragile feature that only works in perfect conditions.
Speech recognition AI and natural language processing
Speech recognition is only one part of a larger system. It depends on natural language processing to turn transcribed words into something a system can actually understand and use.
Automatic speech recognition handles the first step. It converts spoken audio into text. At that point, the system knows what was said, but not what was meant. The output may be technically correct and still be useless without context.
At this point, NLP analyzes the text to interpret meaning, intent, and relationships between words. It helps the system understand whether a sentence is a question, a command, or a statement. It also helps resolve ambiguity, such as whether “book a table” refers to a restaurant reservation or a calendar entry.
Without NLP, speech recognition would stop at transcription. You would get words on a screen, but no understanding of tone, intent, or nuance. With NLP, those words become structured information that software can act on. This is what allows voice systems to route support requests, trigger workflows, and respond appropriately rather than returning raw text.
In practice, ASR and NLP function as a single pipeline. One captures what was said. The other figures out what to do with it. When they work well together, voice becomes an interface rather than a fragile feature that only works in scripted scenarios.
How natural language processing NLP improves speech recognition
Natural language processing strengthens speech recognition by adding understanding on top of transcription. Its role is not to hear words better, but to make sense of what those words mean in real situations.
One of the main ways NLP helps is by interpreting context. Spoken language is often ambiguous, and many words sound the same while carrying different meanings. A basic speech recognition system might correctly transcribe the word “bat,” but it cannot tell whether the speaker is referring to an animal or a piece of sports equipment. NLP examines the surrounding words and the broader sentence to determine which meaning fits the situation.
NLP also resolves ambiguity in everyday commands. A short phrase like “Set an alarm for two” can be interpreted in several ways at the transcription level. The sound may match “two,” “to,” or “too.” NLP analyzes sentence structure and intent to determine that the speaker is referring to a time, not a direction, for example. This step prevents correct transcriptions from turning into incorrect actions.
Accuracy improves when NLP evaluates entire sentences rather than isolated words. It accounts for grammar, common phrases, informal language, and patterns people use in natural speech. In real conversations, where people rarely speak in clean, scripted sentences, this is an extremely important factor.
Modern NLP systems also adapt over time. When a system repeatedly encounters similar phrases from the same user or within the same workflow, it learns how those phrases are typically used. If “Set an alarm for two” consistently refers to a time in past interactions, the system becomes more confident in that interpretation going forward.
Together, speech recognition and NLP turn voice into a usable interface. One captures what was said. The other determines what it means and how the system should respond. Without NLP, speech recognition would remain a transcription tool. With it, spoken language becomes a reliable way to interact with software.
Use cases of speech recognition in businesses
Speech recognition systems show up in many business workflows, from customer support to internal operations.
One of the most common uses is automated customer support. Interactive voice response systems let customers navigate menus using natural speech rather than keypad input. This shortens calls and routes people to the right place without human intervention at the first step.
Virtual agents build on that foundation. These systems use speech recognition to understand customer questions and respond with relevant information or actions. They handle routine requests around the clock, reducing wait times and freeing human agents to focus on complex issues.
Call analytics is another area where speech recognition delivers value. By transcribing customer calls, companies can analyze conversations at scale. This makes it possible to identify recurring problems, track customer sentiment, and spot gaps in service quality that would otherwise be buried in recordings.
Some organizations use speech recognition software for voice biometrics. Instead of relying only on passwords or security questions, systems can authenticate users based on vocal patterns. This adds a layer of security while keeping the customer experience simple.
Multilingual support is increasingly important for global teams and customer bases. Speech recognition enables real-time transcription and translation, which helps people communicate across languages without slowing down meetings or support interactions.
Speech analytics goes a step further than transcription. By analyzing large volumes of recorded calls, companies can extract insights about customer preferences, common objections, and emerging trends. This turns everyday conversations into a source of operational and market intelligence.
Across all of these use cases, speech recognition reduces manual work, shortens response times, and turns spoken interactions into data that systems and teams can actually use.
Benefits of speech recognition for your business
Speech recognition software delivers business value when it is applied to real workflows rather than treated as a feature add-on. The benefits show up quickly once voice becomes a reliable input method.
One clear advantage is improved efficiency. Voice commands allow employees to complete routine actions without switching tools or stopping to type. Over time, those short-term savings add up, giving teams more space to focus on work that requires judgment and attention.
Speech recognition systems also improve the user experience. Voice-based interactions feel more natural and require less effort than navigating menus or forms. For customers, this often means faster resolution and fewer steps to get what they need. For employees, it reduces headaches in day-to-day tasks.
Cost reduction is another practical outcome. Automating parts of customer support, documentation, and data entry reduces the manual work required. Fewer repetitive tasks translate into lower operational overhead and more predictable workflows.
Accessibility improves when voice is available as an input option. Speech recognition makes systems easier to use for people with physical limitations, visual impairments, or situations where hands-free interaction is necessary. This expands who can comfortably interact with your services.
Voice recognition interactions also generate valuable data. Every spoken command or conversation becomes structured input that can be analyzed. Over time, this data reveals patterns in customer behavior, common issues, and unmet needs. Those insights help teams adjust services and processes based on how people actually use them, not how they are assumed to.
The final words
Speech recognition in AI has already changed how people interact with technology, and its role will continue to expand as systems become more accurate and more context-aware. Voice is no longer just a convenience. It is a practical interface that speeds up routine work, and turns everyday conversations into usable data.
That said, the technology is not without limits. Accent variation, background noise, and subtle shifts in meaning still challenge even mature systems. These issues cannot be solved by models alone. They require careful system design, realistic testing, and an understanding of how people actually speak in real environments.
This is where the difference between a demo and a working solution becomes clear. Speech recognition delivers value only when it is adapted to your workflows, your users, and your constraints. Off-the-shelf tools can get you started, but they rarely hold up once real volume and complexity enter the picture.
Whether you are building a voice-enabled assistant, improving customer interactions, or extracting insight from spoken data, the goal should be the same. The system should listen accurately, interpret meaning correctly, and fit naturally into how work already gets done. When speech recognition reaches that point, it stops feeling like technology and starts feeling like a normal part of doing business. Contact us to get more information.



