

Machine Learning (ML) is a large subset of artificial intelligence that studies methods for building learning-capable algorithms. (Wikipedia Definition)
You can also find such a definition. Machine learning is a branch of AI that explores methods that allow computers to improve their performance based on experience.
The first self-learning algorithm-based program was developed by Arthur Samuel in 1952 and was designed to play checkers. Samuel also gave the first definition of the term "machine learning": it is "the field of research in the development of machines that are not preprogrammed."
In 1957, the first neural network model was proposed that implements machine learning algorithms similar to modern ones. A variety of machine learning systems are currently being developed for use in future technologies such as the Internet of Things, the Industrial Internet of Things, the concept of a "smart" city, the creation of uncrewed vehicles, and many others.
The following facts evidence the fact that great hopes are now pinned on machine learning: Google believes that soon its products "will no longer be the result of traditional programming - they will be based on machine learning"; New products like Apple's Siri, Facebook's M, and Amazon's Echo have been built using machine learning. In 1957, the first neural network model was proposed that implements machine learning algorithms similar to modern ones. A variety of machine learning systems are currently being developed for use in future technologies such as the Internet of Things, the Industrial Internet of Things, the concept of a "smart" city, the creation of uncrewed vehicles, and many others.
Now that we have figured out what machine learning is let's look at how to build a machine learning system so that it works effectively for a specific business's specific goals.
What is a machine learning pipeline?
A machine learning pipeline (or system) is a technical infrastructure used to manage and automate machine learning processes. The logic of building a system and choosing what is necessary for this depends only on machine learning tools—pipeline management engineers for training, model alignment, and management during production.
A machine learning model is a result obtained by training a machine algorithm using data. After training is complete, the model produces an output when input data is entered into it. For example, a forecasting algorithm creates a forecasting model. Then, when data is entered into the predictive model, it issues a forecast based on the data used to train the model.
There is a clear distinction between training and running machine learning models in production. But, before we look at how machine learning works in a production environment, let’s first look at the steps involved in preparing a model.
Model preparation process
When developing a model, data engineers work in some development environment specifically designed for machine learning, such as Python, R, etc. And they can train and test the models in the same “sandboxed” environment while writing relatively little code. It is excellent for fast-to-market interactive prototypes.
The machine learning model preparation process consists of 6 steps. This structure represents the simplest way to process data through machine learning.
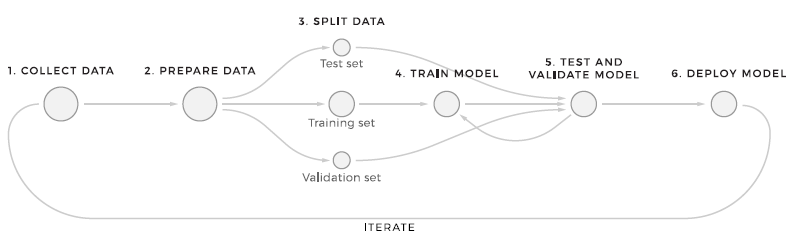
- Collecting the required data. The first thing that any ML workflow starts with is sending incoming data to the store. No transformations are applied to the data at this point, which allows you to keep the original data set unchanged.
NoSQL databases are suitable for storing large amounts of rapidly changing structured and/or unstructured data because they do not contain schemas. They also offer distributed, scalable, replicated data storage. - Data preparation. As soon as the data enters the system, the distributed pipeline looks for differences in format, trends, data correctness, and which data is missing and corrupted and corrects any anomalies. This step also includes the feature development process. There are three main stages in the function pipeline: extract, transform, and select.

Preparing the data is the hardest part of an ML project. Implementing the right design patterns is critical. Also, do not forget that they are converted several times. This is often done manually, namely, formatting, cleaning, labeling, and enriching the data so that the data quality for future models is acceptable. After preparing the data, data scientists begin to design functions. Functions are data values that the model will use in both training and production.
Each feature set is assigned a unique identifier to ensure consistency of functionality - Data separation. At this stage, it is necessary to split the data, first of all, to teach the model and later check how it works with new data. A machine learning system's primary goal is to use an accurate model based on the quality of predicting patterns on data that it has not previously trained on. There are many strategies for this, such as using standard ratios, sequentially, or randomly.
- Model Learning: Here, in turn, it is worth using a subset of the data so that the machine learning algorithm recognizes specific patterns. The model training pipeline works offline and can be triggered by time and by the event. It consists of a library of training model algorithms (linear regression, k-means, decision trees, etc.). The training of the model should be carried out, taking into account the resistance to errors.
- Testing and Validation: Evaluating model performance involves using a test subset of the data to gain a deeper understanding of how accurate the prediction is. By comparing results between tests, the model can be tuned/modified /trained on different data. The training and evaluation steps are repeated several times until the model reaches an acceptable percentage of correct predictions.
- Deployment: Once the selected model is created, it is usually deployed and embedded in the decision-making framework. More than one model can be deployed to ensure a safe transition between the old and new models.
Machine learning pipeline in production
When the model training is done, the next step is to deploy it to the production environment, where the model will make its predictions on the real data, making real commercial effects. The crucial step here is deployment, but performance monitoring is also something that needs to be done on a regular basis.
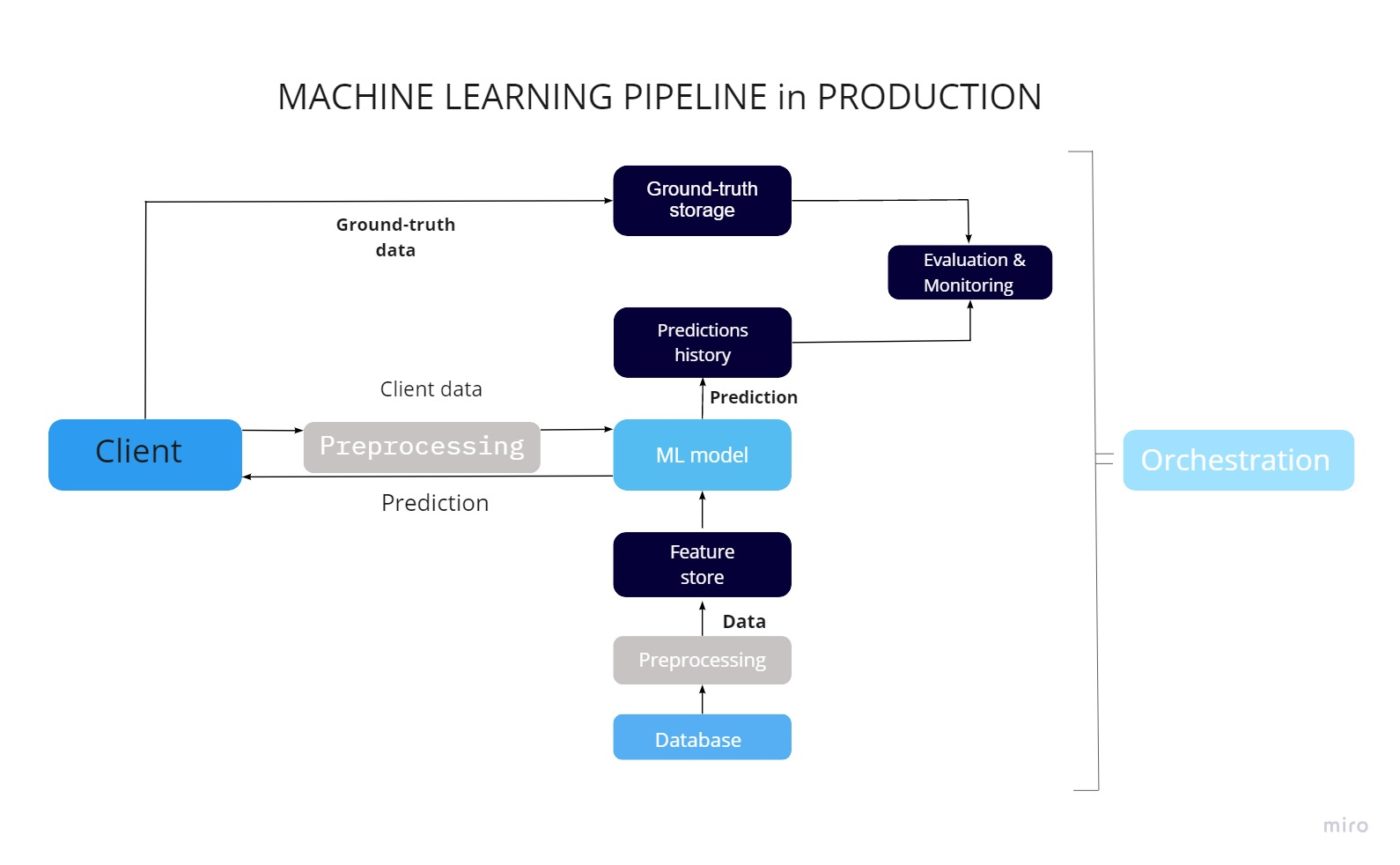
Control over the models, as well as their performance, is essential for the machine learning pipeline. Let's take a look at the general architecture, divide the process into specific actions, and make an overview of the main tools used for particular operations. Please note that there are many types of machine learning systems, and we are talking here based on our experience. We hope that you will have a general idea of how machine learning systems work by the end.
Access to the model prediction data via the application
Let's assume one has an application that either interacts with the clients or other parts of the system. In this case, access to the data will be possible once certain input data is provided. For example, similar products recommendations on the popular eCom marketplaces work in such way, the data about all the visited products is collected during the user journey through the marketplace, this data is sent to the model via API and then the response is given with the list of products that might be interesting for this particular client.
Feature stores and how they work
In some cases, the data can't be directly accessed, in this case, the feature stores can help. The example of the data that can't be directly transferred using the API is the same product recommendation system but based on other users' tastes. We should mention, that the volume of such data can be quite big, so here are two options on how to provide it: batching and streaming.
Batching is basically getting the information in portions, like the pagination. Data streaming on the other hand is data streamed on the go and can be used for parcel tracking, for example, giving the estimation based on the correct location of the delivery vehicle.
Data preprocessing
The data comes from the application client in a raw format. This approach allows the model to read this data; then it must be processed and converted into functions so that the model can use it.
- The function store can also have a dedicated microservice for automatic data preprocessing.
- Data preprocessor: data sent from the application client and function store is formatted, functions are retrieved.
- Making forecasts: after the model receives all the required functionality from the client and the function store, it generates a forecast. It sends it to the client and a separate database for further evaluation.
Storing accurate data and forecasts
It is also essential for us to receive factual data from the client. Based on them, the assessment of the forecasts made by the model and for its further improvement will be carried out. This kind of information is usually stored in a database of valid data.
However, it is not always possible to collect truthful information as well as automate this process. Consider an example, if a customer purchased a product from you, this is a fact and can compare the model's predictions. And what if a client saw your offer, but bought from another seller, in this case, obtaining truthful information is impossible.
Model evaluation and monitoring
ML models deployed in the production environment needs to be monitored and evaluated constantly. To make sure the model delivers the best results we need to:
- Keep prediction results to be as high as possible.
- Analyze the model performance.
- To have an understanding of the model needs to be trained again.
- To have a dashboard with the performance KPIs we have set.
Quite a few open-source libraries available for visualization are the same as some monitoring tools (MLWatcher, for example, for Python, allows it).
Orchestration
Orchestration is the automatic placement, coordination, and management of complex computer systems. Orchestration describes how services should interact with each other using messaging, including business logic and workflow.
Thus, it provides complete control over the deployment of models on the server, managing their operation, data flow management, and activation of training/retraining processes.
Orchestrators use scripts to schedule and execute all of the tasks associated with a production environment's machine learning model. Popular tools used to orchestrate machine learning models are Apache Airflow, Apache Beam, and Kubeflow Pipelines.
Machine learning model retraining pipeline
The data on which the models are trained are outdated due to this, the accuracy of the forecasts decreases. Monitoring tools can be used to track this process. In the case of critically low efficiency, it is necessary to retrain the model using the new data. This process can be made automatic.
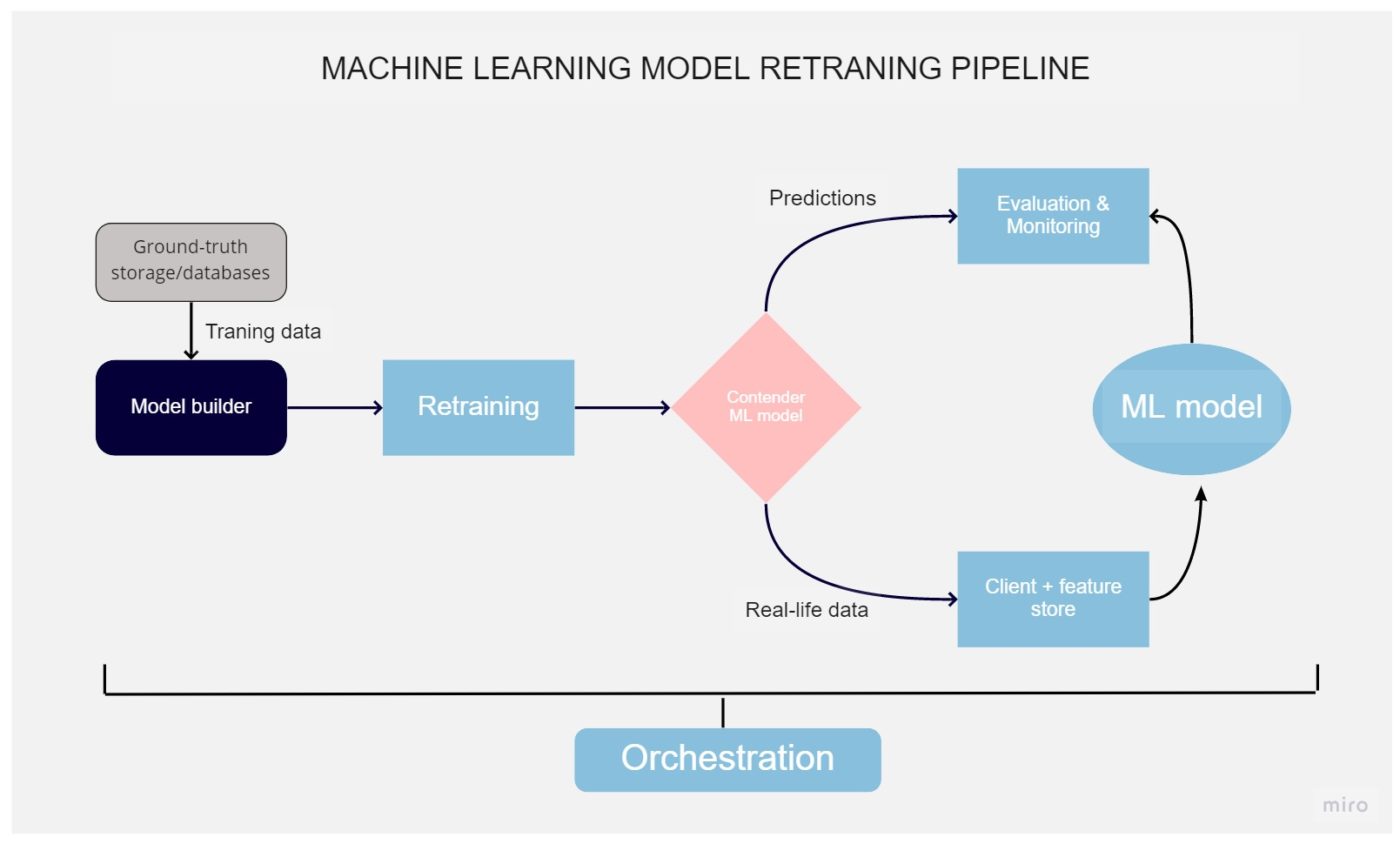
Model retraining
The same as training the model, the retraining process is also a crucial part of the whole life cycle. This process uses the same resources, like training, going through the same steps until the deployment. Still, it's required if the prediction accuracy decreased below the acceptable level that we monitor using the methods mentioned earlier. This doesn't necessarily mean our model works bad but can happen if some new features were introduced on a product that also needs to be included in the ML model.
Retrained model evaluation
The model trained on new data is designed to replace the old one, but before that, it must be compared with fundamental and other indicators, namely accuracy, throughput, and so on.
This procedure is carried out using a unique tool - an evaluator, which checks the model's readiness for production. It evaluates how accurate the predictions are, and using real and reliable data, and it can only compare trained models with already working models. Displaying the results of the challenger model happens using monitoring tools. If a new model performs better than its predecessor, then it is taken into production.
Tools for Machine Learning Pipeline creation
Machine Learning Pipeline is always a custom solution, but some digital tools and platforms can help you build it. So let’s overview some of them for a better understanding of how they can be used.
| Steps For Building Machine Learning Pipeline | Tools Which Can be Used |
| Collecting Data |
Managing the Database – PostgreSQL, MongoDB, DynamoDB, MySQL. Storage – Hadoop, Apache Spark/ Apache Flink. |
| Preparing Data |
The language for scripting – SAS, Python, and R. Processing – MapReduce/ Spark, Hadoop. Data Wrangling Tools – R, Python Pandas |
| Exploring / Visualizing the Data to find the patterns and trends | Python, R, Matlab, and Weka. |
| Modeling the data to do the predictions |
Machine Learning algorithms – Supervised, Unsupervised, Reinforcement, Semi-Supervised and Semi-unsupervised learning. Libraries – Python (Scikit learn) / R (CARET) |
| Interpreting the result | Data Visualization Tools – ggplot, Seaborn, D3.JS, Matplotlib, Tableau |
Why is the machine learning pipeline important?
Automating the model life cycle stages is the most crucial feature of why the machine learning pipeline is used. With the new training data, a workflow starts with data validation, preprocessing, model training, analysis, and deployment. Performing all these steps manually is costly, and there is a possibility of making mistakes. Next, we want to look at the benefits of using machine learning pipelines:
- #1 Ability to focus on new models without supporting existing models: Automated machine learning pipelines negate the need to maintain existing models, which saves time and does not need to run scripts to preprocess the training data manually.
- #2 Preventing errors: In manual machine learning workflows, a common error source is changing the preprocessing stage after model training. To avoid this, you can deploy the model with processing instructions that are different from those trained. These errors can be prevented by using automated workflows.
- #3 Standardization: Standardized machine learning pipelines enhance the data scientist team's experience and enable you to connect to work and quickly find the same development environments. This improves efficiency and reduces the time spent setting up a new project.
The business case for pipelines
The implementation of automated machine learning pipelines leads to improvements in 3 areas:
- More time to develop new models
- Easier processes for updating existing models
- Less time spent playing models.
All these aspects will reduce project costs, and besides, it will help detect potential biases in datasets or trained models. Identifying bias can prevent harm to the people interacting with the model.
To conclude
Machine learning pipelines provide many benefits, but not every data project needs a pipeline. If you want to experiment with how data works, then pipelines are useless in these cases. However, as soon as the model has users (for example, it will be used in an application), it will require constant updates and fine-tuning.
Pipelines also become more important as the machine learning project grows. If the dataset or resource requirements are large, the approaches we discuss to make it easy to scale the infrastructure. If repeatability is essential, this is accomplished through the machine learning pipelines' automation and audit trail.
Wonder how AI capabilities may empower your business? Join our free AI discovery workshop! Contact us to get more information.
FAQ
- Designing of the pipelined processor is complex.
- Instruction latency increases in pipelined processors.
- The throughput of a pipelined processor is difficult to predict.
- The longer the pipeline, the worse the problem of hazard for branch instructions.


