


Table of Contents
If you’re reading this article, you should have probably been thinking about the ways of automatization and optimization of your business processes with BI Software Development.
But even if at this particular moment all your business processes work smoothly, the employee’s working time is planned efficiently, your income is steadily growing, clients are satisfied, and everything seems to be great, we would still recommend you to get familiar with the world of Big Data.
After all, knowledge gives rise to new ideas, and they, in turn, push the business towards growth.
In this article, we will try to give you a better understanding of Big Data, how it can help you get more profit with less cost, discuss benefits and pitfalls, give you some tips on using it wisely, and much more.
But if you doubt whether Big Data suits your case after reading, you are always welcome to contact us and get free advice. We will be happy to find a solution that would help to bring your business to the next level.
What is Big Data, and how does it work?
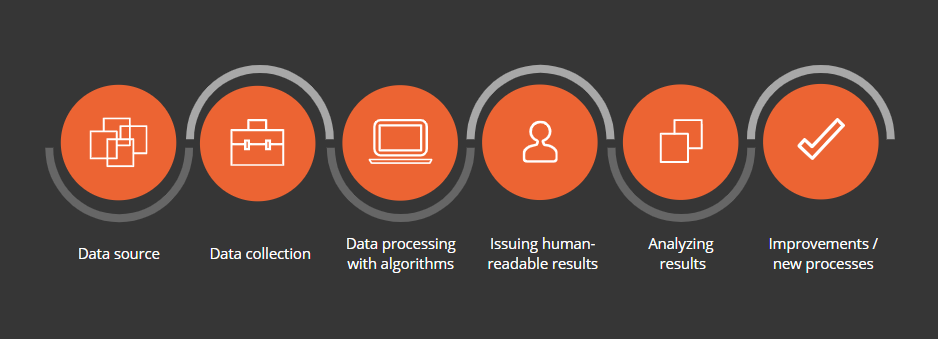
In short, Big Data is a large volume of heterogeneous data that is processed using algorithms, is collected in a human-readable report, and which helps to reveal hidden patterns. (Wiki link)
Although machines carry out work with a large amount of information, this process’s key role is assigned to a person. The analyst is the one who processes the information received and decides how to use it effectively.
It is essential to understand that Big Data is not just a large data volume and is not even Data itself. Big Data should be understood as a principle of data processing that a person cannot cope with.
As you can imagine, data sources can be completely different from shopping at the supermarket and credit card transactions at your bank to data taken from the Hadron Collider’s sensors.
But all the data sources have two things in common. Such data is resource-intensive and difficult to understand. Sometimes it’s almost impossible to analyze it manually.
With the advent of Big Data, a need to introduce fundamentally new approaches arose. It should have been something brand new, completely different from traditional work with incoming data.
So what are the fundamental principles and technologies that underlie working with Big Data today?
“Three pillars” that Big Data relies on

#1 Horizontal scalability
Everything is pretty simple here. The more data is received, the more computing resources are needed. Data processing should be happening without degrading in performance. It means that if the volume of incoming information has doubled – the resources have to be doubled.
#2 Fault tolerance
The more resources you have, the higher risk of their failure is. Therefore, it is essential to consider the likelihood of such accidents and take preventive measures in advance.
#3 Locality of data
It happens that data is stored on one server and processed on another. As data traffic increases, the cost of transferring this data between servers can increase significantly. At this point, a good practice is to keep storage and data processing on one ‘machine’.
Methods and technologies used with Big Data
Before we move on and get familiar with methods and technologies, let’s get to know the definition “cluster.” Since we will meet it further.
In simple words, a cluster is a group of computers (so-called nodes), which are interconnected by a single network. Each node has its RAM and operating system. As a rule, all nodes in a cluster are identical in their architecture and performance.
MapReduce
Most likely, you have already heard this term before. But what does it mean?
This is a model developed by Google that allows distributed computing of enormous data volumes in computer clusters.
First, the data array is being automatically divided into parts and distributed among the cluster nodes. Then each piece is processed parallelly with all the others on a separate node. And at the end, all the parts are combined into a single final result.
The essence of this model can be summarized in three functions. These are Map, Shuffle, Reduce.
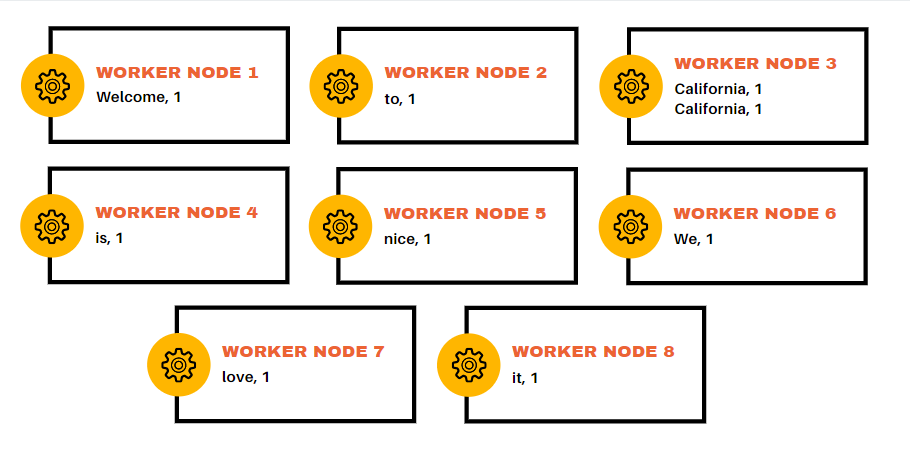
- The Map is a master node of the cluster that receives the amount of data, divides it into parts, and distributes it to the ‘worker’ nodes. Next, each worker node processes local data and writes the temporary storage results in key-value format.
Let’s imagine, we received a large volume which is “Welcome to California California is nice We love it”
The master node distributes data between three worker nodes so that this data is processed in parallel.
Worker node: Welcome to California
Worker node: California is nice
Worker node: We love it
In this example, each node’s task is to split the received data into words and assign them a value “1”. Meaning, in the end, we get a “key” that is a word and a “value” that is ‘1’.
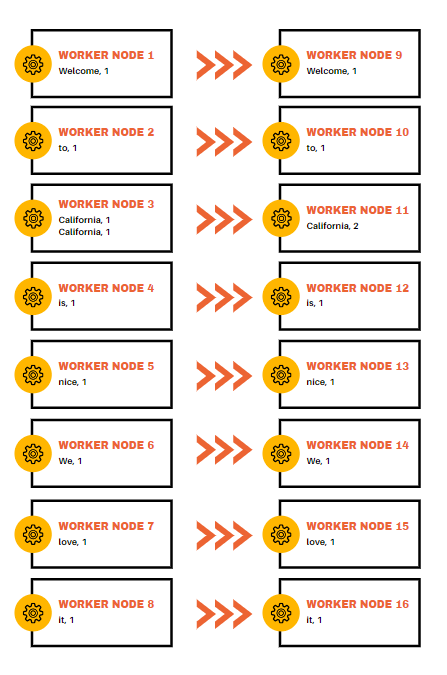
- Shuffle. The results obtained on the first step are grouped by key and distributed to ‘baskets’ (other work nodes). So, one key gets one working node.

- Reduce is a stage of parallel processing of data that was sorted into “baskets” on the previous step. The master node receives intermediate responses from each worker node and writes down the result to the free nodes. It could be shown this way.


Then the output is collected into a single result:
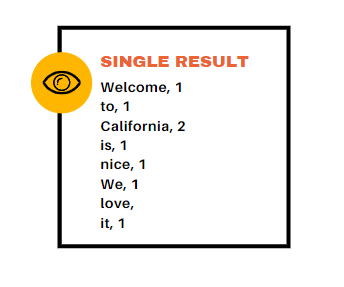
This result is a resolution of the task.
Thus, you can perform completely different operations: process the number of calls to a specific address, distribute searches, and sort large data streams, process network log statistics, and much, much more.
Hadoop
Without going into detail, Hadoop is a set of software solutions for work with Big Data. It is a flexible tool that can be customized for many different tasks.
For example, Hadoop can be used as
- storage of large volumes of data
- a database for third-party software solutions
- a data processing and analysis tool
From a business and management perspective, the third Hadoop function is the most useful one. For example, the program allows you to quickly calculate an enterprise’s risks based on the collected data. Moreover, it is possible to supplement the missing information that allows building more accurate forecasts and statistics.
The main area of Hadoop technology application is the search and contextual mechanisms of high-load Internet resources such as Amazon, Yahoo, Google, AliExpress, and others. The technology helps to analyze search queries and user logs.
R is a perfect language for Big Data.
R is a programming language that is used to analyze large amounts of data. R has become practically the standard for solving statistical problems due to its capabilities and relative ease of use.
NoSQL (Not Only SQL) – a panacea or a disaster?
Although prerequisites for the emergence of NoSQL databases originated much earlier than the appearance of the ‘Big Data’ concept, NoSQL is a perfect match to it.
Such databases are focused on applications whose task is to process a large amount of heterogeneous data with low latency.
But are they a panacea for all the cases? There is no definite answer to this question. Some think that this is. Others consider this technology overrated.
However, one thing is for sure. The experience of implementing non-relational databases has once and for all shown the importance of setting the correct business priorities and goals when introducing new technologies into business.
Some companies, having implemented NoSQL, were able to reduce their expenses significantly. In contrast, others didn’t get benefits but increased costs.
The issue of implementing NoSQL, like any other technology, must be approached systematically, answering at least 3 main questions:
– What problem do we want to solve?
– What result do we want to achieve by introducing this technology?
– What criteria will success be evaluated by?
The implementation of any solution will not be crowned with success unless clear criteria for this success are identified in advance.
Use of Big Data in business
To get an idea of how to apply Big Data correctly, you also need to understand how a new approach differs from the traditional one. To see the differences, please review the scheme below.

Big Data helps to obtain new, previously unavailable information and serves for a deeper understanding of things.
There are many methods and techniques for analyzing Big Data in the modern world. Among the most popular and widely known ones are the following.
- Crowdsourcing
- Data is expanded and classified by people voluntarily. Roughly speaking, this is mutual assistance. And the most striking example is Wikipedia.
It is a data analysis method that allows a machine/robot to learn by solving the same type independently. The machine looks for patterns in the arrays of provided data and selects the most effective solution.
In the modern world, machine learning has found many applications, for example, in face recognition systems and medicine when making diagnoses.
- Simulations
It allows building models of how specific processes would have occurred. They are often used in experiments.
- Analytical data visualization
- Statistical and spatial analysis
And much more.
Almost every business can profit from using Big Data.
For one business, it can be served as a tool for daily routine automation. That, in turn, would free up human resources for more complex and creative work.
For another one, Big Data would become an effective way to save resources. It all depends on the goals set by the business.
If we also look at the areas requiring increased attention, machine algorithms can play a role of additional insurance against human errors. These areas of application include medicine, pharmacology, science, etc.
What are the benefits of using Big Data in business?
When used accurately, Big Data can reward your business with the following benefits:
- A deeper understanding of your target audience and their needs
- Acceleration of interaction with your users and partners
- Increase in customer loyalty
- Personalization of advertisements
- Increase of cross-sells and upsells
- Ability to launch new unique projects
- In-depth study of competitors
- Fraud prevention
- Improve in quality of products and services
- Optimization of internal business processes that can reduce costs and production time
- Forecasting the market situation and reaction of the target audience to marketing strategies
And so on.
Of course, this list is not complete. Each business is unique. Someone else’s experience is good, but only you know your company’s pain points and can decide what needs improvement and investment. You are the only one who can define a goal of Big Data introduction.
But we would love to give you some tips on how to make the right decision!
Tip # 1
First of all, we would like to highlight that increase in earnings through Big Data should not be a goal.
The main goal is to optimize certain processes and cost items, which will lead to an increase in profitability, sales, etc.
Define the problems of your business. Can they be resolved with Big Data? If yes, then step on this path. Otherwise, it can lead to high costs and no profit.
Tip # 2
And even if you are not yet confident about using Big Data, we recommend starting collecting information now.
When you decide to proceed with it, you will already have information to analyze.
Tip # 3
The line between Ad personalization and obsession is fragile.
Big Data will help you find an approach to your target audience. But only the originality of the idea, its value for consumers, and the high quality of the end product will help you build long-term relationships with customers and grow it day after day.
Well, the main advice is – don’t take risks without in-depth research. Entrust it to professionals who can not only complete the task at 100% but also who also have expertise in this matter.
We could help you to make the right and competitive decisions!


